Esta é uma ideia fundamentalmente sólida e certamente pode ajudar, mas (dependendo da sua aplicação específica) pode não ser a ideal. Se não houver muito cruzamento entre diferentes usuários, funcionará bem, mas uma vez que haja o seu o aplicativo se torna cada vez mais complexo e você acabará lendo e gravando em ambos os servidores de qualquer forma.

Adicionar mais servidores, por exemplo, para dividir o alfabeto em quatro em vez de dois, exigirá a modificação do seu código de acesso, e a migração de todos os dados exigirá potencialmente um tempo de inatividade significativo. Quando você atinge esse estágio, você precisa começar a se tornar realmente inteligente.
O próximo passo para muitas pessoas é particionar os dados verticalmente também, o que significa dividir os dados itens de dados individuais que você precisa armazenar em porções diferentes e usar um servidor diferente para cada papel.
O Diagrama 3 mostra um exemplo em que um site permite que seus usuários publiquem atualizações de status e carreguem imagens, e há uma servidor de banco de dados mestre separado para cada uma dessas diferentes tarefas e tipos de dados, em vez de manter todos os dados em um único base de dados.
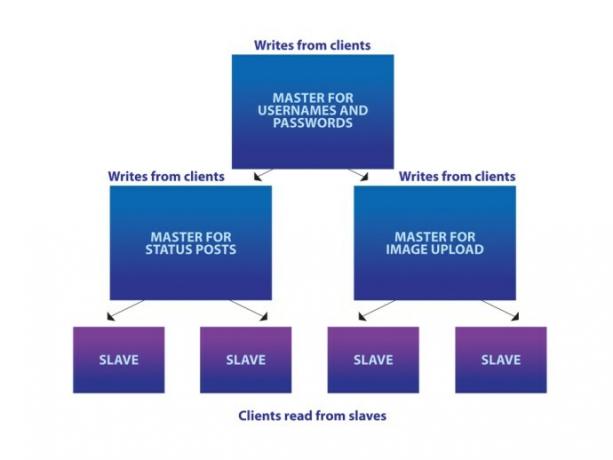
Novamente, esse tipo de arquitetura certamente ajudará, mas muitas vezes você ainda precisará de um banco de dados para conter “dados mestres” que precisam ser compartilhados entre todos. todos os outros – por exemplo, nomes de usuário e senhas neste caso – e uma vez que o servidor fica sobrecarregado, você começa a ficar seriamente sem opções.
Muitas pessoas incrivelmente inteligentes têm pensado neste problema há muito tempo, e uma série de surgiram alternativas, muitas delas construídas em torno do conceito de dados “eventualmente consistentes”. loja.
A ideia aqui é que você tenha várias instâncias de todo o banco de dados, que geralmente são distribuídas geograficamente, um está no Reino Unido, um na costa oeste dos EUA, um na costa leste e assim sobre. Tanto as leituras quanto as gravações podem vir e ir para qualquer um desses armazenamentos e, com o tempo – e esperançosamente, não muito tempo – quaisquer alterações feitas em um são propagadas para todos os outros.
Porém, isso não precisa acontecer de forma absolutamente imediata, daí o termo “eventualmente” consistente.
À primeira vista, isso não parece uma boa ideia, porque certamente você deseja que todos os armazenamentos de dados contenham informações idênticas o tempo todo, não é? Na prática, porém, é uma solução atraente em muitas áreas de aplicação. Primeiro de tudo, “eventualmente” na verdade não precisa significar “dentro de vários dias”, e geralmente uma mudança para qualquer dado seria propagado em um espaço de tempo relativamente curto – normalmente, menos de um segundo.
Para muitas aplicações comerciais, não ter dados novos ou alterados disponíveis de forma absolutamente instantânea não é um problema. Considere um aplicativo como o Facebook: se Alice mudar seu perfil escrevendo para um dos armazenamentos de dados, e Bob não perceber essa mudança por um ou dois segundos, isso será o fim do mundo? Na verdade. A mudança será propagada para o armazenamento de dados que Bob está lendo muito rapidamente e, certamente, na próxima vez que ele atualizar a página, verá o status atualizado.
Por outro lado, você certamente não poderia empregar tal sistema para um site de banco on-line, onde esses poucos segundos de atraso poderiam invalidar completamente uma transação. Mas para a maioria das redes sociais e aplicativos de comércio eletrônico existentes, é bom o suficiente.
NoSQL
Então, qual é essa ideia “NoSQL”? Bem, isso decorre do fato de que a maioria das soluções eventualmente consistentes que existem por aí não usam realmente SQL – Structured Query Language, usada por sistemas de gerenciamento de banco de dados relacional para manipular dados – em todos.

![Como excluir sua conta do LinkedIn [permanentemente]](/f/1bcbdfbb4e73bce6052e81755f765245.png?w=1207&ssl=1?width=100&height=100)

