Attualmente sono impiegato presso Sun Microsystems come istruttore senior, insegnando argomenti relativi a MySQL: amministrazione di database, ottimizzazione delle prestazioni e simili. Questo mi rende, almeno in teoria, una specie di esperto di MySQL, che ora è il più grande sistema di gestione di database relazionali open source al mondo.

Tuttavia, tengo d'occhio anche qualsiasi altra cosa stia accadendo nel mondo dei database, e recentemente è iniziata a emergere una tendenza interessante, spinta dalle esigenze di grandi siti Web come Facebook.
Questa tendenza è diventata nota come "movimento NoSQL" e tenta di affrontare quei problemi che sorgono quando il tentativo di scalare in modo massiccio un sistema di gestione di database relazionali (RDBMS) inizia a fallire giù.
Ecco il problema in poche parole: è molto difficile continuare a scalare un RDBMS una volta superato un determinate dimensioni, soprattutto se stai cercando di distribuire geograficamente i tuoi data center allo stesso modo tempo. I più grandi attori come Google e Amazon sono stati tutti costretti ad affrontare questo problema qualche tempo fa, mentre siti web come Facebook, Digg e altri stanno solo ora incontrando la stessa barriera.
Per capire perché è un tale problema, vale la pena dare un'occhiata ad alcune strategie di ridimensionamento relativamente semplici per vedere perché falliscono.
Quando si ridimensiona un RDBMS tradizionale, in genere inizierai con un singolo server di database (userò MySQL è il mio esempio qui, ma i principi sono simili, se non identici, qualunque RDBMS tu preferire). Funziona bene per un po', ma man mano che il tuo sito web diventa sempre più popolare, il caricamento su questo server aumenta fino al punto in cui inizia a funzionare in modo inaccettabilmente lento.
Il passaggio successivo è normalmente quello di sospendere uno o più server slave dal server del database principale, come mostrato nel diagramma a destra.
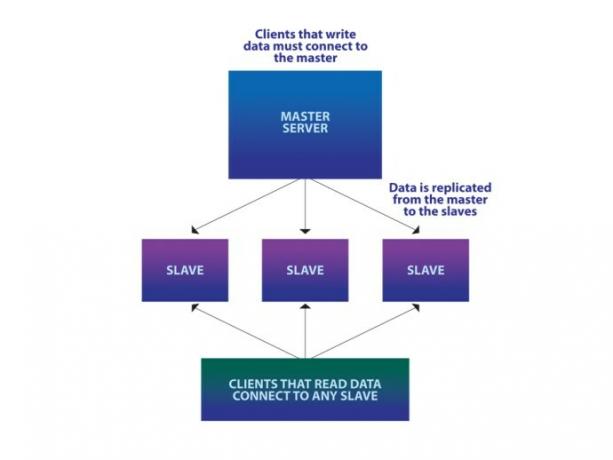
Tutti i dati sul server master vengono replicati automaticamente su questi slave, in modo che qualsiasi applicazione che desideri leggere alcuni dati possa connettersi a uno qualsiasi degli slave disponibili per farlo. Tuttavia, tutte le scritture devono andare al master, perché il flusso di dati è unidirezionale dal master agli slave e non ha senso scrivere su uno slave.
Questo traffico a senso unico inizia a diventare un problema se il set di dati deve essere aggiornato frequentemente: pensa a Facebook come un esempio, in cui le persone devono aggiornare il proprio stato e il proprio profilo, caricare immagini, commentare le pagine degli altri e così via SU. La lettura non è più un problema poiché puoi semplicemente appendere sempre più slave al master, ma con l'aumentare del traffico di scrittura ricomincerà a sommergere il server master.
A questo punto, potresti voler introdurre server master extra, con replica master-master in aggiunta a replica master-slave, e magari appendere alcuni slave a ciascuno di questi master come mostrato nel diagramma al Giusto.

Questo tipo di architettura può aiutare a gestire i carichi, anche se risulta che non è così perfetta come sembra. Potresti pensare che una volta che hai due master sul posto puoi fare il doppio delle scritture al secondo, ma purtroppo non è così grazie a vari problemi (legati al blocco dei file e agli aggiornamenti paralleli) che non ho lo spazio per trattare in modo adeguato Qui. Un tale scenario multimaster può aiutare in una certa misura, ma presto supererai il punto in cui i rendimenti diminuiranno drasticamente.
Partizionamento orizzontale e verticale
La prossima strategia da provare è il ridimensionamento orizzontale, o "sharding", dei dati. L'idea è di mantenere alcuni sottoinsiemi dei tuoi dati su un server e alcuni su uno diverso. Ad esempio, forse potresti archiviare i dati di tutte quelle persone i cui cognomi iniziano con le lettere A-M su un server e quelli che iniziano con N-Z su un altro.



