Saat ini saya bekerja di Sun Microsystems sebagai instruktur senior, mengajarkan topik terkait MySQL – administrasi database, penyesuaian kinerja, dan sejenisnya. Itu membuat saya, setidaknya secara teori, menjadi ahli MySQL, yang sekarang menjadi sistem manajemen basis data relasional sumber terbuka terbesar di dunia.

Namun, saya juga mengawasi apa pun yang terjadi di dunia basis data, dan baru-baru ini tren menarik mulai muncul, didorong oleh kebutuhan situs web besar seperti Facebook.
Tren ini kemudian dikenal sebagai "gerakan NoSQL", dan mencoba untuk mengatasi masalah tersebut muncul ketika upaya untuk meningkatkan secara besar-besaran sistem manajemen basis data relasional (RDBMS) mulai rusak turun.
Inilah masalahnya secara singkat: sangat sulit untuk terus meningkatkan RDBMS setelah Anda lulus ukuran tertentu, terutama jika Anda mencoba mendistribusikan pusat data Anda secara geografis pada waktu yang sama waktu. Pemain terbesar seperti Google dan Amazon semuanya terpaksa menghadapi masalah ini beberapa waktu lalu, sementara situs web seperti Facebook, Digg, dan lainnya baru saja menghadapi penghalang yang sama.
Untuk memahami mengapa ini menjadi masalah, ada baiknya melihat beberapa strategi penskalaan yang relatif sederhana untuk melihat mengapa mereka gagal.
Saat meningkatkan RDBMS tradisional, Anda biasanya akan memulai dengan satu server basis data (saya akan menggunakan MySQL sebagai contoh saya di sini, tetapi prinsipnya serupa, jika tidak identik, mana pun RDBMS Anda lebih menyukai). Ini bekerja dengan baik untuk sementara waktu, tetapi ketika situs web Anda menjadi semakin populer, pemuatan di server ini meningkat ke titik di mana ia mulai bekerja sangat lambat.
Langkah Anda selanjutnya biasanya untuk menggantung satu atau lebih server budak dari server database master seperti yang ditunjukkan pada diagram di sebelah kanan.
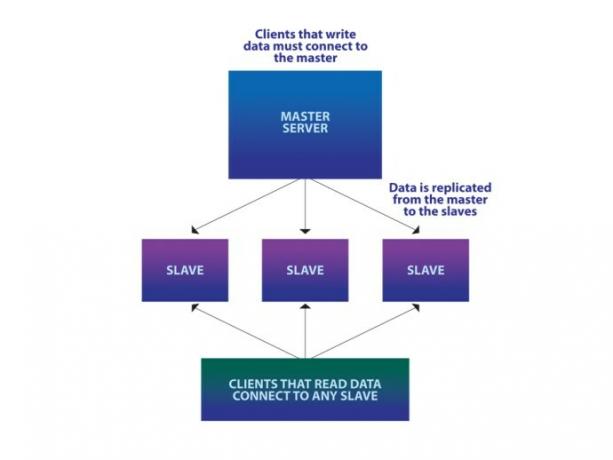
Semua data di server master secara otomatis direplikasi ke budak ini, sehingga aplikasi apa pun yang ingin membaca beberapa data dapat terhubung ke salah satu budak yang tersedia untuk melakukannya. Namun, semua penulisan harus ke master, karena aliran data satu arah dari master ke slave, dan menulis ke slave tidak masuk akal.
Lalu lintas satu arah ini mulai menjadi masalah jika kumpulan data perlu sering diperbarui: pikirkan Facebook sebagai contoh, di mana orang perlu memperbarui status dan profilnya, mengunggah gambar, mengomentari halaman orang lain, dan sebagainya pada. Membaca tidak lagi menjadi masalah karena Anda hanya dapat menggantung lebih banyak budak dari master, tetapi saat lalu lintas tulis meningkat, server master akan mulai membanjiri lagi.
Pada titik ini, Anda mungkin ingin memperkenalkan server master tambahan, dengan replikasi master-master sebagai tambahan replikasi master-budak, dan mungkin menggantung beberapa budak dari masing-masing master ini seperti yang ditunjukkan pada diagram ke Kanan.

Jenis arsitektur ini dapat membantu menangani beban, meskipun ternyata tidak sesempurna kelihatannya. Anda mungkin berpikir bahwa setelah Anda memiliki dua master, Anda dapat melakukan penulisan dua kali per detik, tetapi sayangnya, bukan itu masalahnya berkat berbagai masalah (berkaitan dengan penguncian file dan pembaruan paralel) yang saya tidak punya ruang untuk membahasnya dengan detail yang memadai Di Sini. Skenario multimaster semacam itu mungkin membantu sampai batas tertentu, tetapi Anda akan segera melewati titik pengembalian yang menurun drastis.
Partisi horizontal dan vertikal
Strategi selanjutnya untuk dicoba adalah penskalaan horizontal – atau “sharding” – data. Idenya adalah untuk menyimpan subset tertentu dari data Anda di satu server dan beberapa di server lain. Misalnya, mungkin Anda dapat menyimpan data untuk semua orang yang nama belakangnya dimulai dengan huruf A-M di satu server dan yang dimulai N-Z di server lain.



